So, your organization is engaged in, or reasonably anticipates: litigation defense, regulatory investigation (especially if you're held to GDPR or CCPA), an audit, or another legal dispute.
Now what?
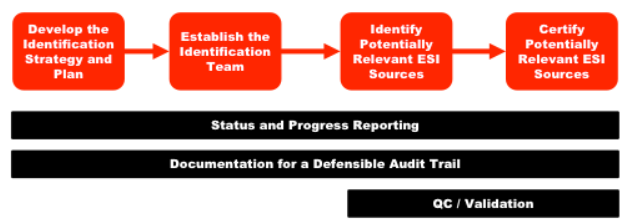
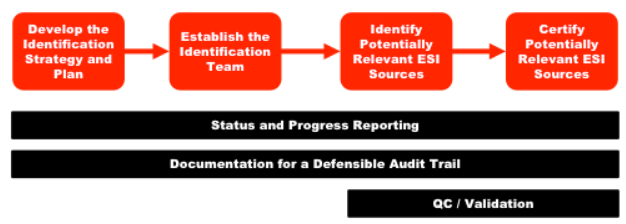
State and federal statutes, court rules, and government regulations each promulgate, frame, and define an organization’s obligations to identify relevant electronically stored information (ESI) when such conflicts arise. According to EDRM, Identification is arguably among the most important responsibilities an organization must undertake in the discovery process.
What is eDiscovery Identification?
Identification means locating potential sources of ESI and determining its scope, breadth, and depth. While this concept isn’t tricky, an organization’s ability to skillfully and comprehensively execute an Identification strategy often proves to be elusive.
The Identification process demands thorough investigation and analysis, the flexibility to pivot as the issues/key players change, and the fortitude to meet nail-bitingly tight deadlines.
As with all legal matters, frameworks are important, but attention to detail is essential. The EDRM Identification Guide provides an outline and comprehensive commentary to assist organizations with designing and implementing an identification plan.
Why does Identification Matter?
A well-executed Identification plan generally allows adverse parties access to the most complete record possible to ensure justice is served and a substantial reduction in overall eDiscovery spend.
Just like implementing a sound Information Governance plan reduces downstream costs, more precise Identification can significantly reduce document review costs, as one example. Additionally, the information gained during the Identification process in one litigation or investigation event can be recycled for use in future events.
If you’re an attorney who’s attended a recent Ethics CLE, you’re well aware of the nightmarish consequences that can await parties who fail to identify and preserve relevant ESI. Adverse inference instructions, monetary fines, and outright dismissals are just a few of the options that await those who engage in discovery misconduct and spoliation.
Although it's rare that organizations are faced with nuclear, case-killing sanctions for failing to identify potentially relevant data, courts do have latitude to do so – especially when the omissions are intentional or otherwise egregious.
The 5 W’s of ESI Identification
Identification can be broken down with a strategy similar to the "5 W’s of Journalism". For purposes of ESI identification, let’s consider:
- WHO has the data?
- WHAT types of data are being created (and destroyed)?
- WHERE does the ESI live?
- WHEN did the dispute(s) at issue occur?
- If information is unable to be identified or is no longer available, WHY?
WHO Has the Data?
To ensure you’re identifying the most relevant and complete data set possible, your Information Governance plan should point you to the appropriate department leaders, employees, and data vendors. The speed and quality of the Identification phase depend on their institutional knowledge and cooperation.
Successfully identifying potential sources of ESI includes classifying the key players with knowledge of and involvement in the dispute, but also pinpointing key stakeholders in human resources, information technology, records management, legal, etc., who are familiar with the people, policies, and data at issue.
One immediate benefit of identifying the key players is that it allows an organization to meet its obligation to provide the opposing party with a list of persons who are likely to have discoverable information. Identifying the key stakeholders will help flesh out the rest of the 5 Ws as well. For example, speaking with stakeholders in the legal department can assist in quickly determining who manages and enforces the organization’s legal holds, and whether one has been created for the present dispute.
The Federal Rules of Civil Procedure (FRCP) require each party to provide “a description by category and location, of all documents, ESI, and tangible things that are in the possession, custody, or control of the party and that the disclosing party may use to support its claims or defenses.” In order to do so, an organization will often conduct a combination of custodial and records management interviews for the major players, while distributing surveys to canvas the peripheral figures for additional information.
WHAT types of data are being created (and destroyed)?
At the onset of the Identification process, you’re probably already well aware of some of your organization’s most frequently used data types. Emails, Microsoft Office files, PDFs, video files, and audio files are nearly universally recognizable data types that are commonly created and distributed in the normal course of business. But these types of data could plausibly be just the tip of the identification iceberg. So what else needs to be identified?
If you’re looking for a complete checklist of all the ESI data types that are potentially relevant and available, you certainly won’t find it in the Federal Rules of Civil Procedure (“FRCP”). The FRCP is intentionally silent regarding the definition of ESI due to the ever-changing and rapidly evolving landscape of technological innovation. Below are some additional data types and some non-exhaustive examples that may need to be explored during the Identification stage:
- Social Media – Facebook, Twitter, LinkedIn, Instagram
- Internet of Things (IoT) data – “Smart” technologies, including Amazon Echo, Fitbit, Nest thermostats
- Video Conferencing and Other Collaboration Tools – Zoom, GoToMeeting, Microsoft Teams, Slack, Sharefile
- Text/Instant Messaging – Facebook Messenger, WhatsApp, WeChat
- Industry-Specific Applications – AutoCAD, Illustrator, Medical Records platforms, Salesforce
- Outdated “Legacy” data – Data types and applications that are no longer used by an organization and/or are no longer supported by the manufacturer.
- Paper Documents
Your key players and stakeholders will likely be able to guide the inquiry into which unexpected and unique data types have been (and are being) used. It’s possible that only certain data types may even be relevant to your dispute. Keep in mind that parties generally have the ability to negotiate the types of data that need to be searched during the Rule 26(f) meet and confer process.
WHERE does the ESI live?
Determining where your organization’s data is located is another critical aspect of Identification, and it necessitates careful discussions with the key players and stakeholders about where they store data.
Some of the more common locations for identifying potentially relevant data are (alphabetically): backup tapes, cell phones (company-owned and BYOD), custodial computer hard drives (company-owned and BYOD), email servers, external media (e.g., CDs, DVDs, flash drives), filing cabinets, IoT devices, servers (including company intranet/extranet), voicemail stores.
Not everything you need to identify will necessarily be on-premises. Increasingly, at least some organizational data is likely to reside in the cloud. Effectuating a defensible legal hold will, in large part, depend on how completely you identify the location of the data at issue.
WHEN did the dispute(s) at issue occur?
Identification is often said to begin when an organization’s duty to preserve potentially relevant ESI is triggered (i.e., litigation or an investigation is “reasonably anticipated”), but determining when the obligation to identify data ends is equally important.
Ascertaining the potentially relevant time span further narrows the universe of data you need to identify and limits the who, what, and where inquiries that need to be made. For example, if a Request for Production (RFP) is limited to events that occurred from 1950 through 1985, it’s highly unlikely you’ll be able to identify any pertinent emails that need to be produced.
If information is unable to be identified or is no longer available, WHY?
Not everything you identify throughout this process will be preserved, let alone producible.
- Perhaps there was a fire that destroyed a repository of paper documents
- There might be inaccessible legacy server data that was lost when your data management vendor abruptly closed up shop and disappeared
- Maybe a key former employee with critical knowledge of the dispute passed away before litigation was filed
- You might even find that a prior statute or regulation allowed your organization to delete data after a certain time period
It’s imperative to record and certify the steps you’ve taken throughout the Identification process in case your methods and results are challenged.
For more information on the Identification process, check out the EDRM Identification Guide, reach out if you'd like to have a conversation, and keep your eyes peeled for future Proteus blog posts on this subject and many more that will save you time and lower your expenses.

